
7 Aug
2019
7 Aug
'19
9:46 p.m.
Hi everyone,
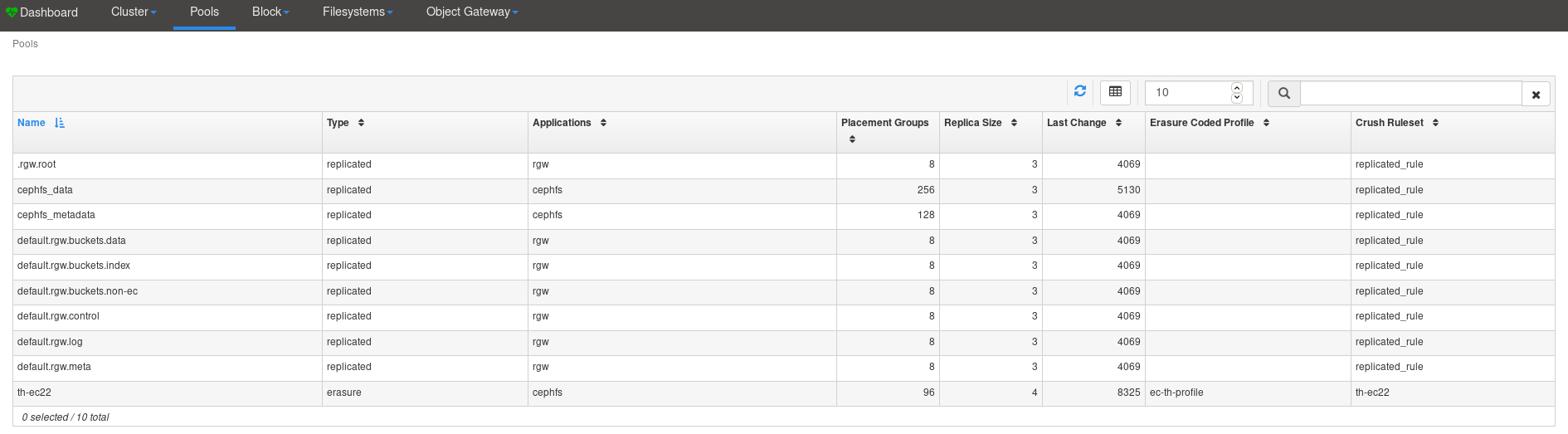
When I started setting up a test cluster, I created a cephfs_data pool
since I thought I was going to use the replicated type for the pool.
This turned out not to be to most ideal choice when it comes to usable
disk space. So I decided to create another erasure coded pool with
k=2;m=2 which I did. Please see the attached log file. I also attached
the output of the pools from the dashboard.
The problem is this. Whenever an OSD needs to be brought down, the
cluster is going to rebalance and enter the degraded mode. The rebalance
of the cluster takes a while since all the PG's need to be
redistributed. Now I could use something like:
|ceph osd ||set| |noout && ceph osd ||set| |norebalance|
However, I want to be able to have the cluster recovered much faster but
cephfs_data pool which has a lot of PG's which I cannot reduce (not able
in mimic) is keeping the cluster busy. This pool isn't used for storing
any data and I am not sure if I can remove this pool without effecting
the th-ec22 EC pool.
Anyone any thoughs on this?
In case I provided insufficient or missing information, please let me
know. I'd gladly share those with you.
--
Met vriendelijke groeten, Kind regards
Valentin Bajrami
Target Holding
{kind=link}