
29 Oct
2020
29 Oct
'20
12:07 p.m.
Hi all,
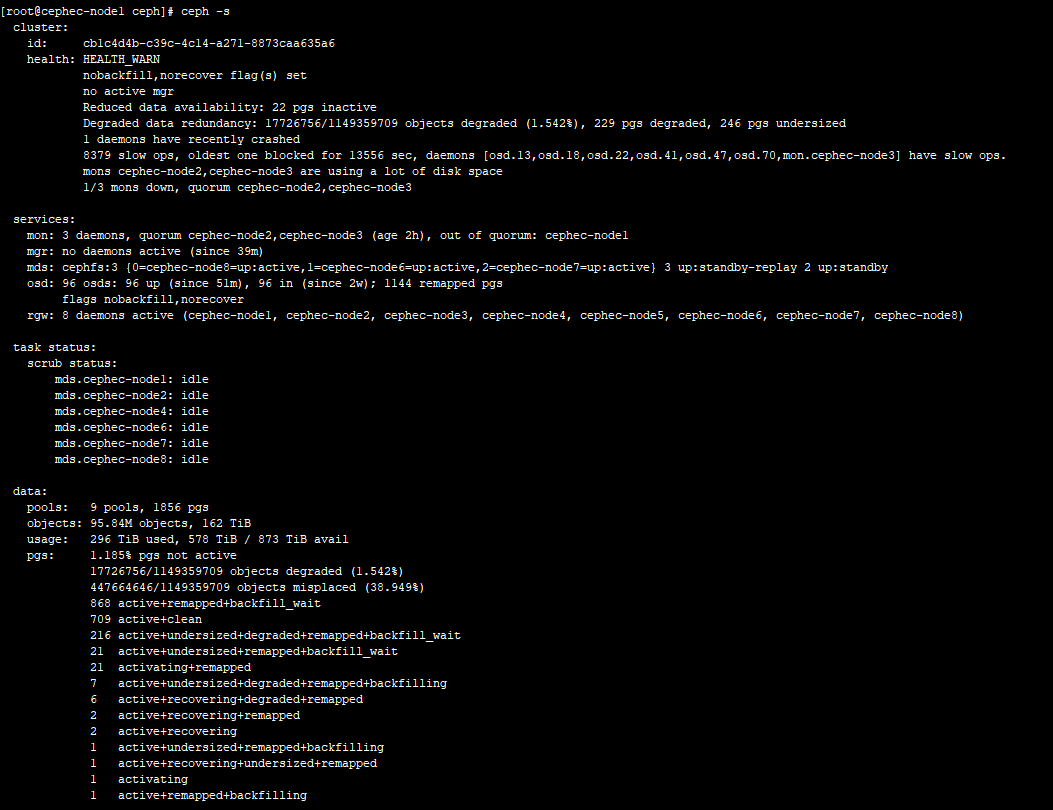
My cluster is in wrong state. SST files in /var/lib/ceph/mon/xxx/store.db
continue growing. It claims mon are using a lot of disk space.
I set "mon compact on start = true" and restart one of the monitors. But
it started and campacting for a long time, seems it has no end.
[image: image.png]
{kind=link}
29 Oct
29 Oct
12:08 p.m.
My cluster is 12.2.12, with all sata disks.
the space of store.db:
[image: image.png]
How can I deal with it?
Zhenshi Zhou <deaderzzs(a)gmail.com> 于2020年10月29日周四 下午2:37写道:
Hi all,
My cluster is in wrong state. SST files in /var/lib/ceph/mon/xxx/store.db
continue growing. It claims mon are using a lot of disk space.
I set "mon compact on start = true" and restart one of the monitors. But
it started and campacting for a long time, seems it has no end.
[image: image.png]
{kind=link}
{kind=link}
12:11 p.m.
MISTAKE: version is 14.2.12
Zhenshi Zhou <deaderzzs(a)gmail.com> 于2020年10月29日周四 下午2:38写道:
My cluster is 12.2.12, with all sata disks.
the space of store.db:
[image: image.png]
How can I deal with it?
Zhenshi Zhou <deaderzzs(a)gmail.com> 于2020年10月29日周四 下午2:37写道:
Hi all,
My cluster is in wrong state. SST files in /var/lib/ceph/mon/xxx/store.db
continue growing. It claims mon are using a lot of disk space.
I set "mon compact on start = true" and restart one of the monitors. But
it started and campacting for a long time, seems it has no end.
[image: image.png]
{kind=link}
{kind=link}

12:56 p.m.
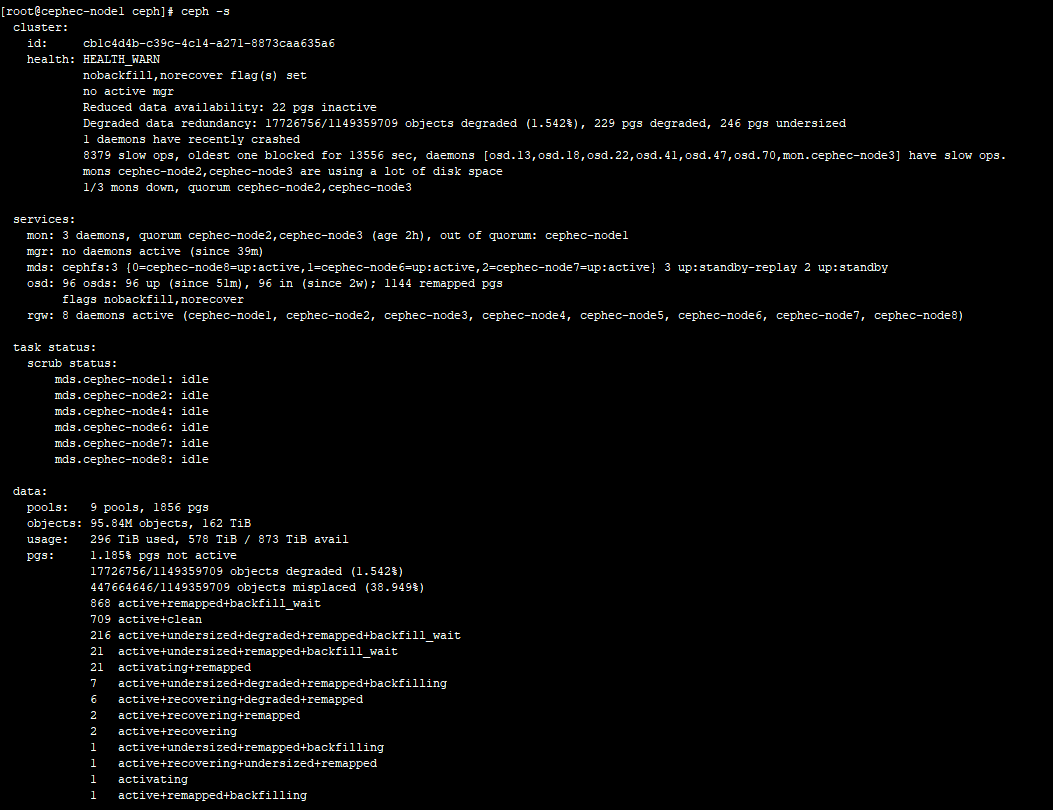
Your problem is the overall cluster health. The MONs store cluster history information
that will be trimmed once it reaches HEALTH_OK. Restarting the MONs only makes things
worse right now. The health status is a mess, no MGR, a bunch of PGs inactive, etc. This
is what you need to resolve. How did your cluster end up like this?
It looks like all OSDs are up and in. You need to find out
- why there are inactive PGs
- why there are incomplete PGs
This usually happens when OSDs go missing.
Best regards,
=================
Frank Schilder
AIT Risø Campus
Bygning 109, rum S14
________________________________________
From: Zhenshi Zhou <deaderzzs(a)gmail.com>
Sent: 29 October 2020 07:37:19
To: ceph-users
Subject: [ceph-users] monitor sst files continue growing
Hi all,
My cluster is in wrong state. SST files in /var/lib/ceph/mon/xxx/store.db
continue growing. It claims mon are using a lot of disk space.
I set "mon compact on start = true" and restart one of the monitors. But
it started and campacting for a long time, seems it has no end.
[image.png]
12:59 p.m.
MGR is stopped by me cause it took too much memories.
For pg status, I added some OSDs in this cluster, and it
Frank Schilder <frans(a)dtu.dk> 于2020年10月29日周四 下午3:27写道:
Your problem is the overall cluster health. The MONs
store cluster history
information that will be trimmed once it reaches HEALTH_OK. Restarting the
MONs only makes things worse right now. The health status is a mess, no
MGR, a bunch of PGs inactive, etc. This is what you need to resolve. How
did your cluster end up like this?
It looks like all OSDs are up and in. You need to find out
- why there are inactive PGs
- why there are incomplete PGs
This usually happens when OSDs go missing.
Best regards,
=================
Frank Schilder
AIT Risø Campus
Bygning 109, rum S14
________________________________________
From: Zhenshi Zhou <deaderzzs(a)gmail.com>
Sent: 29 October 2020 07:37:19
To: ceph-users
Subject: [ceph-users] monitor sst files continue growing
Hi all,
My cluster is in wrong state. SST files in /var/lib/ceph/mon/xxx/store.db
continue growing. It claims mon are using a lot of disk space.
I set "mon compact on start = true" and restart one of the monitors. But
it started and campacting for a long time, seems it has no end.
[image.png]
1 p.m.
After add OSDs into the cluster, the recovery and backfill progress has not
finished yet
Zhenshi Zhou <deaderzzs(a)gmail.com> 于2020年10月29日周四 下午3:29写道:
MGR is stopped by me cause it took too much memories.
For pg status, I added some OSDs in this cluster, and it
Frank Schilder <frans(a)dtu.dk> 于2020年10月29日周四 下午3:27写道:
Your problem is the overall cluster health. The
MONs store cluster
history information that will be trimmed once it reaches HEALTH_OK.
Restarting the MONs only makes things worse right now. The health status is
a mess, no MGR, a bunch of PGs inactive, etc. This is what you need to
resolve. How did your cluster end up like this?
It looks like all OSDs are up and in. You need to find out
- why there are inactive PGs
- why there are incomplete PGs
This usually happens when OSDs go missing.
Best regards,
=================
Frank Schilder
AIT Risø Campus
Bygning 109, rum S14
________________________________________
From: Zhenshi Zhou <deaderzzs(a)gmail.com>
Sent: 29 October 2020 07:37:19
To: ceph-users
Subject: [ceph-users] monitor sst files continue growing
Hi all,
My cluster is in wrong state. SST files in /var/lib/ceph/mon/xxx/store.db
continue growing. It claims mon are using a lot of disk space.
I set "mon compact on start = true" and restart one of the monitors. But
it started and campacting for a long time, seems it has no end.
[image.png]
1:26 p.m.
This does not explain incomplete and inactive PGs. Are you hitting
https://tracker.ceph.com/issues/46847 (see also thread "Ceph does not recover from
OSD restart"? In that case, temporarily stopping and restarting all new OSDs might
help.
Best regards,
=================
Frank Schilder
AIT Risø Campus
Bygning 109, rum S14
________________________________________
From: Zhenshi Zhou <deaderzzs(a)gmail.com>
Sent: 29 October 2020 08:30:25
To: Frank Schilder
Cc: ceph-users
Subject: Re: [ceph-users] monitor sst files continue growing
After add OSDs into the cluster, the recovery and backfill progress has not finished yet
Zhenshi Zhou <deaderzzs@gmail.com<mailto:deaderzzs@gmail.com>> 于2020年10月29日周四
下午3:29写道:
MGR is stopped by me cause it took too much memories.
For pg status, I added some OSDs in this cluster, and it
Frank Schilder <frans@dtu.dk<mailto:frans@dtu.dk>> 于2020年10月29日周四 下午3:27写道:
Your problem is the overall cluster health. The MONs store cluster history information
that will be trimmed once it reaches HEALTH_OK. Restarting the MONs only makes things
worse right now. The health status is a mess, no MGR, a bunch of PGs inactive, etc. This
is what you need to resolve. How did your cluster end up like this?
It looks like all OSDs are up and in. You need to find out
- why there are inactive PGs
- why there are incomplete PGs
This usually happens when OSDs go missing.
Best regards,
=================
Frank Schilder
AIT Risø Campus
Bygning 109, rum S14
________________________________________
From: Zhenshi Zhou <deaderzzs@gmail.com<mailto:deaderzzs@gmail.com>>
Sent: 29 October 2020 07:37:19
To: ceph-users
Subject: [ceph-users] monitor sst files continue growing
Hi all,
My cluster is in wrong state. SST files in /var/lib/ceph/mon/xxx/store.db
continue growing. It claims mon are using a lot of disk space.
I set "mon compact on start = true" and restart one of the monitors. But
it started and campacting for a long time, seems it has no end.
[image.png]
2:14 p.m.
I reset the pg_num after adding osd, it made some pg inactive(in
activating state)
Frank Schilder <frans(a)dtu.dk> 于2020年10月29日周四 下午3:56写道:
This does not explain incomplete and inactive PGs. Are
you hitting
https://tracker.ceph.com/issues/46847 (see also thread "Ceph does not
recover from OSD restart"? In that case, temporarily stopping and
restarting all new OSDs might help.
Best regards,
=================
Frank Schilder
AIT Risø Campus
Bygning 109, rum S14
________________________________________
From: Zhenshi Zhou <deaderzzs(a)gmail.com>
Sent: 29 October 2020 08:30:25
To: Frank Schilder
Cc: ceph-users
Subject: Re: [ceph-users] monitor sst files continue growing
After add OSDs into the cluster, the recovery and backfill progress has
not finished yet
Zhenshi Zhou <deaderzzs@gmail.com<mailto:deaderzzs@gmail.com>>
于2020年10月29日周四 下午3:29写道:
MGR is stopped by me cause it took too much memories.
For pg status, I added some OSDs in this cluster, and it
Frank Schilder <frans@dtu.dk<mailto:frans@dtu.dk>> 于2020年10月29日周四
下午3:27写道:
Your problem is the overall cluster health. The MONs store cluster history
information that will be trimmed once it reaches HEALTH_OK. Restarting the
MONs only makes things worse right now. The health status is a mess, no
MGR, a bunch of PGs inactive, etc. This is what you need to resolve. How
did your cluster end up like this?
It looks like all OSDs are up and in. You need to find out
- why there are inactive PGs
- why there are incomplete PGs
This usually happens when OSDs go missing.
Best regards,
=================
Frank Schilder
AIT Risø Campus
Bygning 109, rum S14
________________________________________
From: Zhenshi Zhou <deaderzzs@gmail.com<mailto:deaderzzs@gmail.com>>
Sent: 29 October 2020 07:37:19
To: ceph-users
Subject: [ceph-users] monitor sst files continue growing
Hi all,
My cluster is in wrong state. SST files in /var/lib/ceph/mon/xxx/store.db
continue growing. It claims mon are using a lot of disk space.
I set "mon compact on start = true" and restart one of the monitors. But
it started and campacting for a long time, seems it has no end.
[image.png]
4:45 p.m.
I think you really need to sit down and explain the full story. Dropping one-liners with
new information will not work via e-mail.
I have never heard of the problem you are facing, so you did something that possibly
no-one else has done before. Unless we know the full history from the last time the
cluster was health_ok until now, it will almost certainly not be possible to figure out
what is going on via e-mail.
Usually, setting "norebalance" and "norecovery" should stop any
recovery IO and allow the PGs to peer. If they do not become active, something is wrong
and the information we got so far does not give a clue what this could be.
Please post the output of "ceph health detail", "ceph osd pool stats"
and "ceph osd pool ls detail" and a log of actions and results since last
health_ok status here, maybe it gives a clue what is going on.
Best regards,
=================
Frank Schilder
AIT Risø Campus
Bygning 109, rum S14
________________________________________
From: Zhenshi Zhou <deaderzzs(a)gmail.com>
Sent: 29 October 2020 09:44:14
To: Frank Schilder
Cc: ceph-users
Subject: Re: [ceph-users] monitor sst files continue growing
I reset the pg_num after adding osd, it made some pg inactive(in activating state)
Frank Schilder <frans@dtu.dk<mailto:frans@dtu.dk>> 于2020年10月29日周四 下午3:56写道:
This does not explain incomplete and inactive PGs. Are you hitting
https://tracker.ceph.com/issues/46847 (see also thread "Ceph does not recover from
OSD restart"? In that case, temporarily stopping and restarting all new OSDs might
help.
Best regards,
=================
Frank Schilder
AIT Risø Campus
Bygning 109, rum S14
________________________________________
From: Zhenshi Zhou <deaderzzs@gmail.com<mailto:deaderzzs@gmail.com>>
Sent: 29 October 2020 08:30:25
To: Frank Schilder
Cc: ceph-users
Subject: Re: [ceph-users] monitor sst files continue growing
After add OSDs into the cluster, the recovery and backfill progress has not finished yet
Zhenshi Zhou
<deaderzzs@gmail.com<mailto:deaderzzs@gmail.com><mailto:deaderzzs@gmail.com<mailto:deaderzzs@gmail.com>>>
于2020年10月29日周四 下午3:29写道:
MGR is stopped by me cause it took too much memories.
For pg status, I added some OSDs in this cluster, and it
Frank Schilder
<frans@dtu.dk<mailto:frans@dtu.dk><mailto:frans@dtu.dk<mailto:frans@dtu.dk>>>
于2020年10月29日周四 下午3:27写道:
Your problem is the overall cluster health. The MONs store cluster history information
that will be trimmed once it reaches HEALTH_OK. Restarting the MONs only makes things
worse right now. The health status is a mess, no MGR, a bunch of PGs inactive, etc. This
is what you need to resolve. How did your cluster end up like this?
It looks like all OSDs are up and in. You need to find out
- why there are inactive PGs
- why there are incomplete PGs
This usually happens when OSDs go missing.
Best regards,
=================
Frank Schilder
AIT Risø Campus
Bygning 109, rum S14
________________________________________
From: Zhenshi Zhou
<deaderzzs@gmail.com<mailto:deaderzzs@gmail.com><mailto:deaderzzs@gmail.com<mailto:deaderzzs@gmail.com>>>
Sent: 29 October 2020 07:37:19
To: ceph-users
Subject: [ceph-users] monitor sst files continue growing
Hi all,
My cluster is in wrong state. SST files in /var/lib/ceph/mon/xxx/store.db
continue growing. It claims mon are using a lot of disk space.
I set "mon compact on start = true" and restart one of the monitors. But
it started and campacting for a long time, seems it has no end.
[image.png]
5:59 p.m.
Hi,
I was so anxious a few hours ago cause the sst files were growing so fast
and I don't think
the space on mon servers could afford it.
Let me talk it from the beginning. I have a cluster with OSD deployed on
SATA(7200rpm).
10T each OSD and I used ec pool for more space.I added new OSDs into the
cluster last
week and it has recovered well so far. After that, while the cluster is
still recovering, I increased the pg_num.
Besides that, the clients still write data to the server all the time.
And the cluster became unhealthy last night. Some osds were down and one
mon was down.
Then I found the mon servers' root directories were lack of free space. The
sst files in /var/lib/ceph/mon/ceph-xxx/store.db/
were growing rapidly.
Frank Schilder <frans(a)dtu.dk> 于2020年10月29日周四 下午7:15写道:
I think you really need to sit down and explain the
full story. Dropping
one-liners with new information will not work via e-mail.
I have never heard of the problem you are facing, so you did something
that possibly no-one else has done before. Unless we know the full history
from the last time the cluster was health_ok until now, it will almost
certainly not be possible to figure out what is going on via e-mail.
Usually, setting "norebalance" and "norecovery" should stop any
recovery
IO and allow the PGs to peer. If they do not become active, something is
wrong and the information we got so far does not give a clue what this
could be.
Please post the output of "ceph health detail", "ceph osd pool stats"
and
"ceph osd pool ls detail" and a log of actions and results since last
health_ok status here, maybe it gives a clue what is going on.
Best regards,
=================
Frank Schilder
AIT Risø Campus
Bygning 109, rum S14
________________________________________
From: Zhenshi Zhou <deaderzzs(a)gmail.com>
Sent: 29 October 2020 09:44:14
To: Frank Schilder
Cc: ceph-users
Subject: Re: [ceph-users] monitor sst files continue growing
I reset the pg_num after adding osd, it made some pg inactive(in
activating state)
Frank Schilder <frans@dtu.dk<mailto:frans@dtu.dk>> 于2020年10月29日周四
下午3:56写道:
This does not explain incomplete and inactive PGs. Are you hitting
https://tracker.ceph.com/issues/46847 (see also thread "Ceph does not
recover from OSD restart"? In that case, temporarily stopping and
restarting all new OSDs might help.
Best regards,
=================
Frank Schilder
AIT Risø Campus
Bygning 109, rum S14
________________________________________
From: Zhenshi Zhou <deaderzzs@gmail.com<mailto:deaderzzs@gmail.com>>
Sent: 29 October 2020 08:30:25
To: Frank Schilder
Cc: ceph-users
Subject: Re: [ceph-users] monitor sst files continue growing
After add OSDs into the cluster, the recovery and backfill progress has
not finished yet
Zhenshi Zhou <deaderzzs@gmail.com<mailto:deaderzzs@gmail.com><mailto:
deaderzzs@gmail.com<mailto:deaderzzs@gmail.com>>> 于2020年10月29日周四 下午3:29写道:
MGR is stopped by me cause it took too much memories.
For pg status, I added some OSDs in this cluster, and it
Frank Schilder <frans@dtu.dk<mailto:frans@dtu.dk><mailto:frans@dtu.dk
<mailto:frans@dtu.dk>>> 于2020年10月29日周四 下午3:27写道:
Your problem is the overall cluster health. The MONs store cluster history
information that will be trimmed once it reaches HEALTH_OK. Restarting the
MONs only makes things worse right now. The health status is a mess, no
MGR, a bunch of PGs inactive, etc. This is what you need to resolve. How
did your cluster end up like this?
It looks like all OSDs are up and in. You need to find out
- why there are inactive PGs
- why there are incomplete PGs
This usually happens when OSDs go missing.
Best regards,
=================
Frank Schilder
AIT Risø Campus
Bygning 109, rum S14
________________________________________
From: Zhenshi Zhou <deaderzzs@gmail.com<mailto:deaderzzs@gmail.com
<mailto:deaderzzs@gmail.com<mailto:deaderzzs@gmail.com>>>
Sent: 29
October 2020 07:37:19
To: ceph-users
Subject: [ceph-users] monitor sst files continue growing
Hi all,
My cluster is in wrong state. SST files in /var/lib/ceph/mon/xxx/store.db
continue growing. It claims mon are using a lot of disk space.
I set "mon compact on start = true" and restart one of the monitors. But
it started and campacting for a long time, seems it has no end.
[image.png]
6:08 p.m.
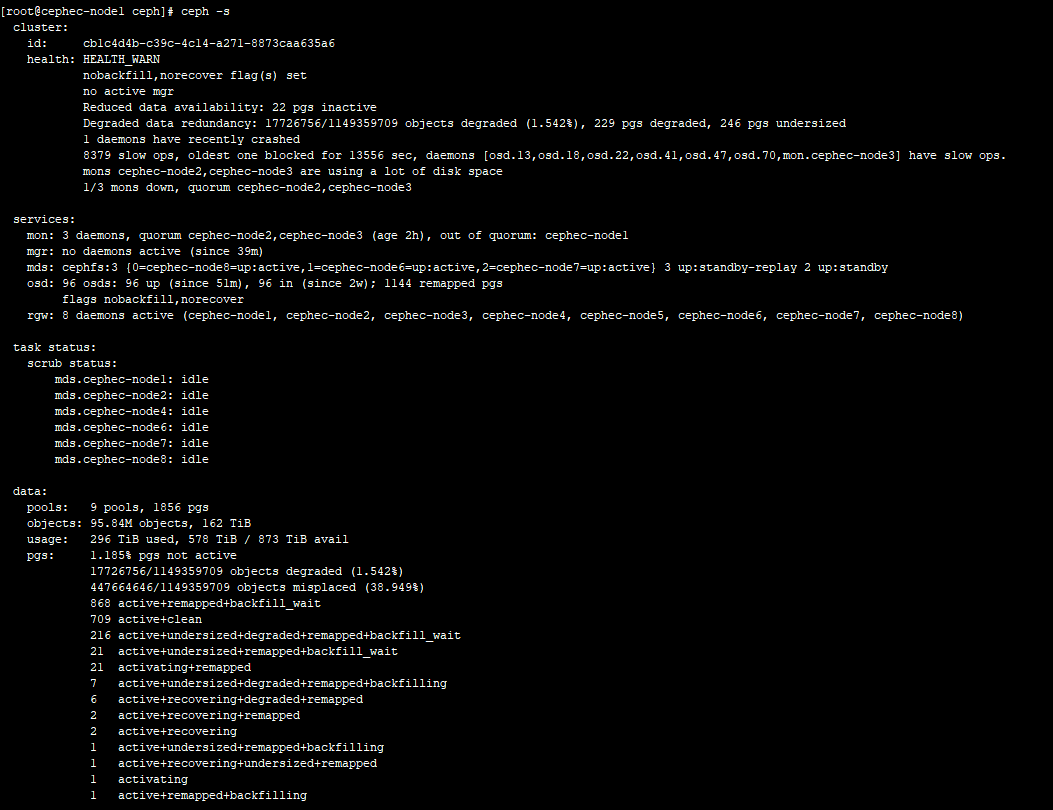
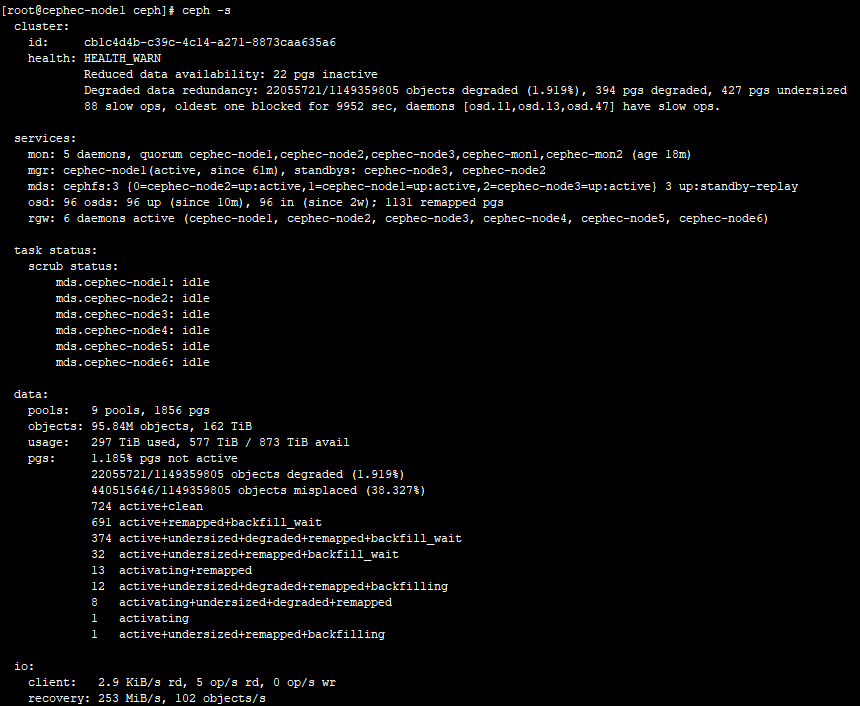
I then follow someone's guidance, add 'mon compact on start = true' to the
config and restart one mon.
That mon has not joined the cluster until I added two mon deployed on
virtual machines with ssd into
the cluster.
And now the cluster is fine except the pg status.
[image: image.png]
[image: image.png]
Zhenshi Zhou <deaderzzs(a)gmail.com> 于2020年10月29日周四 下午8:29写道:
Hi,
I was so anxious a few hours ago cause the sst files were growing so fast
and I don't think
the space on mon servers could afford it.
Let me talk it from the beginning. I have a cluster with OSD deployed on
SATA(7200rpm).
10T each OSD and I used ec pool for more space.I added new OSDs into the
cluster last
week and it has recovered well so far. After that, while the cluster is
still recovering, I increased the pg_num.
Besides that, the clients still write data to the server all the time.
And the cluster became unhealthy last night. Some osds were down and one
mon was down.
Then I found the mon servers' root directories were lack of free space.
The sst files in /var/lib/ceph/mon/ceph-xxx/store.db/
were growing rapidly.
Frank Schilder <frans(a)dtu.dk> 于2020年10月29日周四 下午7:15写道:
I think you really need to sit down and explain
the full story. Dropping
one-liners with new information will not work via e-mail.
I have never heard of the problem you are facing, so you did something
that possibly no-one else has done before. Unless we know the full history
from the last time the cluster was health_ok until now, it will almost
certainly not be possible to figure out what is going on via e-mail.
Usually, setting "norebalance" and "norecovery" should stop any
recovery
IO and allow the PGs to peer. If they do not become active, something is
wrong and the information we got so far does not give a clue what this
could be.
Please post the output of "ceph health detail", "ceph osd pool stats"
and
"ceph osd pool ls detail" and a log of actions and results since last
health_ok status here, maybe it gives a clue what is going on.
Best regards,
=================
Frank Schilder
AIT Risø Campus
Bygning 109, rum S14
________________________________________
From: Zhenshi Zhou <deaderzzs(a)gmail.com>
Sent: 29 October 2020 09:44:14
To: Frank Schilder
Cc: ceph-users
Subject: Re: [ceph-users] monitor sst files continue growing
I reset the pg_num after adding osd, it made some pg inactive(in
activating state)
Frank Schilder <frans@dtu.dk<mailto:frans@dtu.dk>> 于2020年10月29日周四
下午3:56写道:
This does not explain incomplete and inactive PGs. Are you hitting
https://tracker.ceph.com/issues/46847 (see also thread "Ceph does not
recover from OSD restart"? In that case, temporarily stopping and
restarting all new OSDs might help.
Best regards,
=================
Frank Schilder
AIT Risø Campus
Bygning 109, rum S14
________________________________________
From: Zhenshi Zhou <deaderzzs@gmail.com<mailto:deaderzzs@gmail.com>>
Sent: 29 October 2020 08:30:25
To: Frank Schilder
Cc: ceph-users
Subject: Re: [ceph-users] monitor sst files continue growing
After add OSDs into the cluster, the recovery and backfill progress has
not finished yet
Zhenshi Zhou <deaderzzs@gmail.com<mailto:deaderzzs@gmail.com><mailto:
deaderzzs@gmail.com<mailto:deaderzzs@gmail.com>>> 于2020年10月29日周四
下午3:29写道:
MGR is stopped by me cause it took too much memories.
For pg status, I added some OSDs in this cluster, and it
Frank Schilder <frans@dtu.dk<mailto:frans@dtu.dk><mailto:frans@dtu.dk
<mailto:frans@dtu.dk>>> 于2020年10月29日周四 下午3:27写道:
Your problem is the overall cluster health. The MONs store cluster
history information that will be trimmed once it reaches HEALTH_OK.
Restarting the MONs only makes things worse right now. The health status is
a mess, no MGR, a bunch of PGs inactive, etc. This is what you need to
resolve. How did your cluster end up like this?
It looks like all OSDs are up and in. You need to find out
- why there are inactive PGs
- why there are incomplete PGs
This usually happens when OSDs go missing.
Best regards,
=================
Frank Schilder
AIT Risø Campus
Bygning 109, rum S14
________________________________________
From: Zhenshi Zhou <deaderzzs@gmail.com<mailto:deaderzzs@gmail.com
<mailto:deaderzzs@gmail.com<mailto:deaderzzs@gmail.com>>>
Sent: 29
October 2020 07:37:19
To: ceph-users
Subject: [ceph-users] monitor sst files continue growing
Hi all,
My cluster is in wrong state. SST files in /var/lib/ceph/mon/xxx/store.db
continue growing. It claims mon are using a lot of disk space.
I set "mon compact on start = true" and restart one of the monitors. But
it started and campacting for a long time, seems it has no end.
[image.png]
{kind=link}
{kind=link}

8:23 p.m.
We hit this issue over the weekend on our HDD backed EC Nautilus cluster while removing a
single OSD. We also did not have any luck using compaction. The mon-logs filled up our
entire root disk on the mon servers and we were running on a single monitor for hours
while we tried to finish recovery and reclaim space. The past couple weeks we also noticed
"pg not scubbed in time" errors but are unsure if they are related. I'm
still the exact cause of this(other than the general misplaced/degraded objects) and what
kind of growth is acceptable for these store.db files.
In order to get our downed mons restarted, we ended up backing up and coping the
/var/lib/ceph/mon/* contents to a remote host, setting up an sshfs mount to that new host
with large NVME and SSDs, ensuring the mount paths were owned by ceph, then clearing up
enough space on the monitor host to start the service. This allowed our store.db directory
to grow freely until the misplaced/degraded objects could recover and monitors all
rejoined eventually.
11:59 p.m.
Hi Alex,
We found that there were a huge number of keys in the "logm" and
"osdmap"
table
while using ceph-monstore-tool. I think that could be the root cause.
Well, some pages also say that disable 'insight' module can resolve this
issue, but
I checked our cluster and we didn't enable this module. check this page
<https://tracker.ceph.com/issues/39955>.
Anyway, our cluster is unhealthy though, it just need time keep recovering
data :)
Thanks
Alex Gracie <alexandergracie17(a)gmail.com> 于2020年10月29日周四 下午10:57写道:
We hit this issue over the weekend on our HDD backed
EC Nautilus cluster
while removing a single OSD. We also did not have any luck using
compaction. The mon-logs filled up our entire root disk on the mon servers
and we were running on a single monitor for hours while we tried to finish
recovery and reclaim space. The past couple weeks we also noticed "pg not
scubbed in time" errors but are unsure if they are related. I'm still the
exact cause of this(other than the general misplaced/degraded objects) and
what kind of growth is acceptable for these store.db files.
In order to get our downed mons restarted, we ended up backing up and
coping the /var/lib/ceph/mon/* contents to a remote host, setting up an
sshfs mount to that new host with large NVME and SSDs, ensuring the mount
paths were owned by ceph, then clearing up enough space on the monitor host
to start the service. This allowed our store.db directory to grow freely
until the misplaced/degraded objects could recover and monitors all
rejoined eventually.
_______________________________________________
ceph-users mailing list -- ceph-users(a)ceph.io
To unsubscribe send an email to ceph-users-leave(a)ceph.io

30 Oct
30 Oct
2:09 p.m.
On 29/10/2020 19:29, Zhenshi Zhou wrote:
Hi Alex,
We found that there were a huge number of keys in the "logm" and
"osdmap"
table
while using ceph-monstore-tool. I think that could be the root cause.
But that is exactly how Ceph works. It might need that very old OSDMap
to get all the PGs clean again. An OSD which has been gone for a very
long time and needs to catch up to make a PG clean.
If not all PGs are active+clean you will and can see the MON databases
grow rapidly.
Therefor I always deploy 1TB SSDs in all Monitors. Not expensive anymore
and they give breathing room.
I always deploy physical and dedicated machines for Monitors just to
prevent these cases.
Wido
> Well, some pages also say that disable 'insight' module can resolve this
> issue, but
> I checked our cluster and we didn't enable this module. check this page
> <https://tracker.ceph.com/issues/39955>.
>
> Anyway, our cluster is unhealthy though, it just need time keep recovering
> data :)
>
> Thanks
>
> Alex Gracie <alexandergracie17(a)gmail.com> 于2020年10月29日周四 下午10:57写道:
>
>> We hit this issue over the weekend on our HDD backed EC Nautilus cluster
>> while removing a single OSD. We also did not have any luck using
>> compaction. The mon-logs filled up our entire root disk on the mon servers
>> and we were running on a single monitor for hours while we tried to finish
>> recovery and reclaim space. The past couple weeks we also noticed "pg not
>> scubbed in time" errors but are unsure if they are related. I'm still
the
>> exact cause of this(other than the general misplaced/degraded objects) and
>> what kind of growth is acceptable for these store.db files.
>>
>> In order to get our downed mons restarted, we ended up backing up and
>> coping the /var/lib/ceph/mon/* contents to a remote host, setting up an
>> sshfs mount to that new host with large NVME and SSDs, ensuring the mount
>> paths were owned by ceph, then clearing up enough space on the monitor host
>> to start the service. This allowed our store.db directory to grow freely
>> until the misplaced/degraded objects could recover and monitors all
>> rejoined eventually.
>> _______________________________________________
>> ceph-users mailing list -- ceph-users(a)ceph.io
>> To unsubscribe send an email to ceph-users-leave(a)ceph.io
>>
> _______________________________________________
> ceph-users mailing list -- ceph-users(a)ceph.io
> To unsubscribe send an email to ceph-users-leave(a)ceph.io
>
14 Nov
14 Nov
10:14 a.m.
Hi Wido,
thanks for the explanation. I think the root cause is the disks are too
slow for campaction.
I add two new mon with ssd to the cluter to speed it up and the issue
resolved.
That's a good advice and I have plan to migrate my mon to bigger SSD disks.
Thanks again.
Wido den Hollander <wido(a)42on.com> 于2020年10月30日周五 下午4:39写道:
On 29/10/2020 19:29, Zhenshi Zhou wrote:
Hi Alex,
We found that there were a huge number of keys in the "logm" and
"osdmap"
table
while using ceph-monstore-tool. I think that could be the root cause.
But that is exactly how Ceph works. It might need that very old OSDMap
to get all the PGs clean again. An OSD which has been gone for a very
long time and needs to catch up to make a PG clean.
If not all PGs are active+clean you will and can see the MON databases
grow rapidly.
Therefor I always deploy 1TB SSDs in all Monitors. Not expensive anymore
and they give breathing room.
I always deploy physical and dedicated machines for Monitors just to
prevent these cases.
Wido
Well, some pages also say that disable
'insight' module can resolve this
issue, but
I checked our cluster and we didn't enable this module. check this page
<https://tracker.ceph.com/issues/39955>.
Anyway, our cluster is unhealthy though, it just need time keep
recovering
data :)
Thanks
Alex Gracie <alexandergracie17(a)gmail.com> 于2020年10月29日周四 下午10:57写道:
> We hit this issue over the weekend on our HDD backed EC Nautilus cluster
> while removing a single OSD. We also did not have any luck using
> compaction. The mon-logs filled up our entire root disk on the mon
servers
> and we were running on a single monitor for
hours while we tried to
finish
> recovery and reclaim space. The past couple
weeks we also noticed "pg
not
> scubbed in time" errors but are unsure
if they are related. I'm still
the
> exact cause of this(other than the general
misplaced/degraded objects)
and
> what kind of growth is acceptable for these
store.db files.
>
> In order to get our downed mons restarted, we ended up backing up and
> coping the /var/lib/ceph/mon/* contents to a remote host, setting up an
> sshfs mount to that new host with large NVME and SSDs, ensuring the
mount
> paths were owned by ceph, then clearing up
enough space on the monitor
host
to start
the service. This allowed our store.db directory to grow freely
until the misplaced/degraded objects could recover and monitors all
rejoined eventually.
_______________________________________________
ceph-users mailing list -- ceph-users(a)ceph.io
To unsubscribe send an email to ceph-users-leave(a)ceph.io
_______________________________________________
ceph-users mailing list -- ceph-users(a)ceph.io
To unsubscribe send an email to ceph-users-leave(a)ceph.io
1260
days inactive
1276
days old
14 comments
4 participants
participants (4)
-
 Alex Gracie
Alex Gracie -
 Frank Schilder
Frank Schilder -
 Wido den Hollander
Wido den Hollander -
 Zhenshi Zhou
Zhenshi Zhou